As discussed in Section 4.0, the classifier selection approach to classifier combination involves some “oracle” that dynamically determines which component classifier (or, occasionally, classifiers) is best suited to classify each particular input pattern. The decision of the selected classifier is then output as the overall classification of the entire on ensemble.
Classifier selection has a relatively long history, with Rastrigin and Erenstein presenting an approach not all that different from what is often done today in 1981. Nonetheless, classifier selection has not yet achieved the same popularity as classifier fusion, despite the excellent performance of many of the selection-based systems that have been implemented. The surprisingly low diffusion of selection techniques may be due to the fact that much of the early research was performed in the former Soviet Union, and has not been made generally available in translated form to Western researchers until relatively recently. Recent Western interest in classifier selection has been triggered by the work of Woods et al. (1997).
Component classifiers may themselves act as the oracle by outputting an estimate of confidence in their own decisions. For example, an ensemble of k-nn classifiers with the same k may each output the number of neighbours that belong to the class that they each choose, and the final classification of the ensemble is taken to be that of the classifier whose choice represents the highest proportion of its k nearest neighbours. An alternative approach with such distance-based classifiers is to weight the certainty contribution of each nearest neighbour based on its distance from the given test point.
Cascade classification is a variant of classifier selection. With this approach, the classifiers are linked into a sequential chain and each classifier is capable of claiming that it is uncertain of the correct classification. Only one classifier is active at a time. If the active classifier is unsure of a particular classification, it then passes the problem to the next classifier in the ensemble and goes dormant itself. This can continue down the chain of classifiers if none are able to make a decision that they are confident in. If none of the classifiers is able to make a classification with reasonable certainty, then the ensemble outputs a result of unknown, which can be better in many cases than a classification that is likely to be false.
Cascade systems can be an efficient approach to ensemble classification, as many input patterns will hopefully be able to be successfully classified by the first classifier, with the additional computational demands of processing by further classifiers only required when a particularly difficult input is encountered. This is analogous to a typical human classification scenario, where an individual expert typically classifies patterns alone, but can consult colleagues if a particularly ambiguous pattern is encountered in order to take advantage of their added expertise for this particularly difficult pattern.
The above approaches are called “decision-dependent estimates,” because the classifier selection of the oracle is based on actual classifications produced by one or more component classifiers. Another approach, termed “decision-independent estimates,” selects the classifier to use before any classifications are actually made. Restrigin and Erenstein (1981) have proposed such an approach, named the potential functions estimate. In this approach, the feature space is seen as a field and each point in the data set contributes to the “potential” at a given location in feature space. A distance based classifier’s competence for a given input pattern can therefore be measured by comparing the location of the pattern’s location in feature space with the distribution of the classifier’s training points and the corresponding potential. The best classifier can therefore be estimated before any classifications are actually made.
Dynamically estimating the competence of each classifier for each input pattern could be too computationally expensive for some real-time applications. It is therefore sometimes appropriate to pre-calculate regions of competence in feature space for each classifier immediately following training. The classifier to be selected for a given input pattern can then be rapidly chosen based on which classifier’s region of competence the given pattern’s features fall into.
Although this approach can significantly speed up computation, pre-computation of regions of competence can be difficult when using some types of classifiers, particularly since it is usually impossible to exhaustively anticipate all possible input patterns. This approach can therefore sometimes decrease classification accuracy relative to dynamically selecting classifiers based on actual input patterns. Of course, it can also be argued that this is actually beneficial, as the smoothing of selection calculations could help to compensate for overtraining.
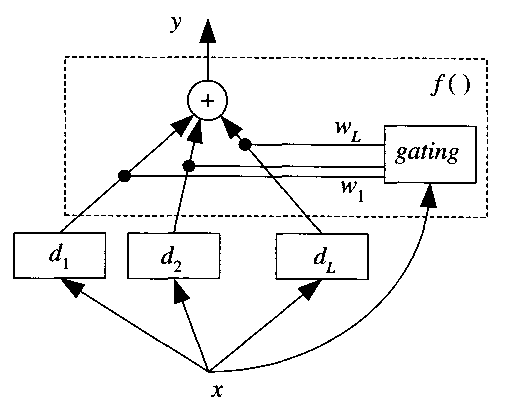
The mixture of experts approach makes use of a separate oracle classifier to determine the degree of participation of each component classifier in the final ensemble decision. The oracle classifier sees the entire input feature set and uses it to select classifiers for each input pattern. The oracle may perform binary gating or may assign weights to each classifier. This architecture has been most often proposed in connection with neural networks. Although each component classifier is typically trained on only a subset of the available features, this does not mean that it might not be fruitful to consider variants where all component classifiers see all of the feature space, as long as one ensures enough diversity among the classifiers. In any case, the gated or weighted outputs of each component classifier can be combined using any of the multiplicity of available classifier fusion techniques (see Section 5). The mixture of experts architecture is shown in figure 6.1. This approach is also sometimes referred to as stacking.
Figure 6.1: The mixture of experts architecture. Each component classifier, d1 through dL, is assigned a weight, w1 through wL, by the gating, or oracle classifier. Any of a number of classifier fusion techniques can then be applied to the weighted classifications in order to arrive at an ensemble classification. (Alpaydin 2004, p. 364).
![]()
Next: Additional methodologies
![]()
Last modified: April 18, 2005.
-top of page-