The “Vocoder” was originally developed in the 1930s as a hardware system for speech analysis and resynthesis. The name comes from “voice encoder”.
From a source-filter model
perspective, the Vocoder is composed of a bank of band-pass (or resonance) filters that model the formants of our vocal mechanism. The settings for these filters are derived from an input speech signal (the “modulator”).
The input signal to be “vocoded” is referred to as the “carrier”. The carrier signal can be recorded or synthesized. To produce “speech-like” results, the carrier is typically an impulse train for vowel sounds and noise for fricative sounds.
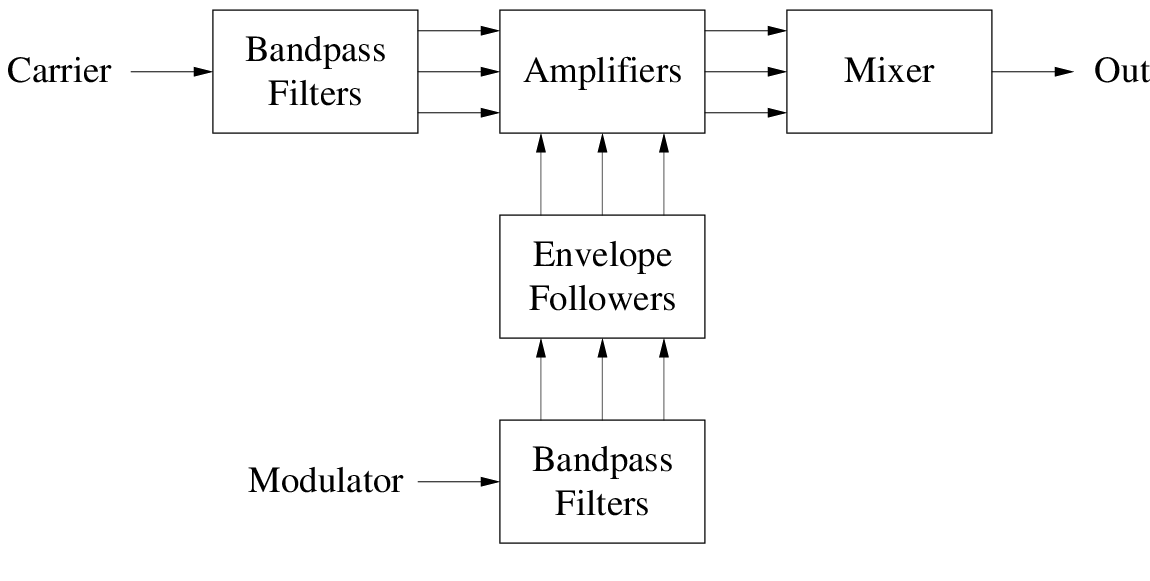
As diagrammed in Fig. 3, the vocoder uses two banks of bandpass filters. The first bank estimates frequency parameters from a given modulator input, while the second bank is used to process the carrier input. The derived modulator bandpass settings control the gains applied at the ouput of the carrier bandpass filters.
Early and “classic” vocoders use a fixed number of bandpass filters (usually 8 - 16) with fixed center frequencies.
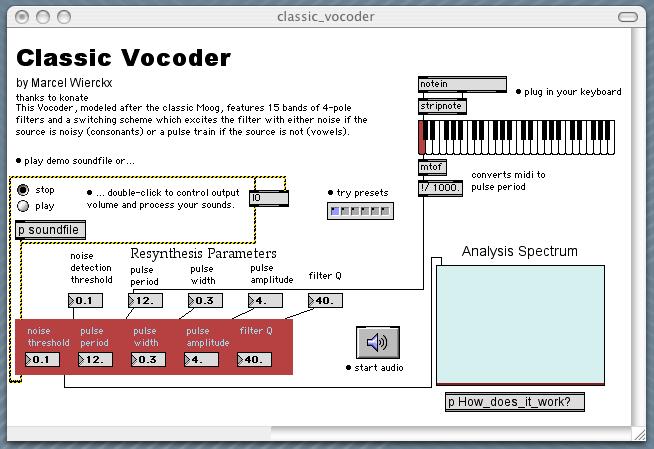
The Max/MSP “Classic Vocoder” shown below (found in the examples/effects/ directory of the Max/MSP distribution) is implemented in this way.
Classic vocoders have a “mechanical” quality to them that has been exploited for musical purposes by a broad range of musicians and composers.
Modern vocoders intended for use in “high-quality” communications (cell phones, ...) typically use linear prediction techniques to estimate the carrier (and residual) parameters. In this case, the center frequencies and number of band-pass filters used are not fixed.